Die Leistungsfähigkeit von Apache Kafka: Rationalisierung der Datenverarbeitung in Echtzeit
Veröffentlicht am

In der heutigen digitalen Welt wird die Echtzeit-Datenverarbeitung für Unternehmen immer wichtiger, um wettbewerbsfähig zu bleiben. Apache Kafka ist eine Open-Source-Plattform für verteiltes Ereignis-Streaming, mit der Sie Daten in Echtzeit streamen können. In diesem Blog werden wir die Leistungsfähigkeit von Apache Kafka erkunden und wie es die Datenverarbeitung in Echtzeit rationalisieren kann.
Was ist Apache Kafka?

Quelle : kai-waehner.de
Apache Kafka ist eine verteilte Streaming-Plattform, mit der Sie Datenströme veröffentlichen und abonnieren können. Sie wurde erstmals 2011 von LinkedIn entwickelt und später zu einem Open-Source-Projekt der Apache Software Foundation. Kafka ist darauf ausgelegt, große Datenmengen in Echtzeit zu verarbeiten und kann für eine Vielzahl von Anwendungsfällen wie Datenpipelines, Echtzeitanalysen und ereignisgesteuerte Architekturen verwendet werden.
Architektur von Apache Kafka
Die Architektur von Apache Kafka basiert auf dem Publish-Subscribe-Modell. Sie besteht aus drei Hauptkomponenten: Produzenten, Themen und Konsumenten. Produzenten sind für die Veröffentlichung von Datensätzen in einem Topic verantwortlich, während Konsumenten ein Topic abonnieren und Datensätze von ihm empfangen. Kafka-Broker fungieren als Nachrichtenvermittler zwischen Produzenten und Konsumenten und stellen sicher, dass die Daten auf eine fehlertolerante und skalierbare Weise verteilt werden.
Anwendungsfälle von Apache Kafka

Quelle : kafka.apache.org
Apache Kafka kann für eine breite Palette von Anwendungsfällen eingesetzt werden. Ein häufiger Anwendungsfall ist der Aufbau von Datenpipelines. Kafka kann verwendet werden, um Daten zwischen verschiedenen Systemen und Anwendungen in Echtzeit zu übertragen. Ein weiterer Anwendungsfall ist die Echtzeit-Analytik. Kafka kann verwendet werden, um Daten in Echtzeit an Analysesysteme zu übertragen, so dass Unternehmen schneller datengestützte Entscheidungen treffen können. Kafka kann auch für ereignisgesteuerte Architekturen verwendet werden, bei denen Anwendungen durch Ereignisse in Echtzeit ausgelöst werden.
Vorteile von Apache Kafka
Einer der Hauptvorteile von Apache Kafka ist seine Skalierbarkeit. Kafka kann große Datenmengen verarbeiten und lässt sich problemlos horizontal skalieren, um steigende Lasten zu bewältigen. Kafka ist außerdem fehlertolerant und stellt sicher, dass im Falle von Ausfällen keine Daten verloren gehen. Ein weiterer Vorteil von Kafka ist seine geringe Latenzzeit. Kafka ist für die Datenverarbeitung in Echtzeit konzipiert und kann Daten in Echtzeit an die Verbraucher liefern, was es zu einer idealen Wahl für Anwendungsfälle wie Echtzeitanalysen macht.
Erste Schritte mit Apache Kafka
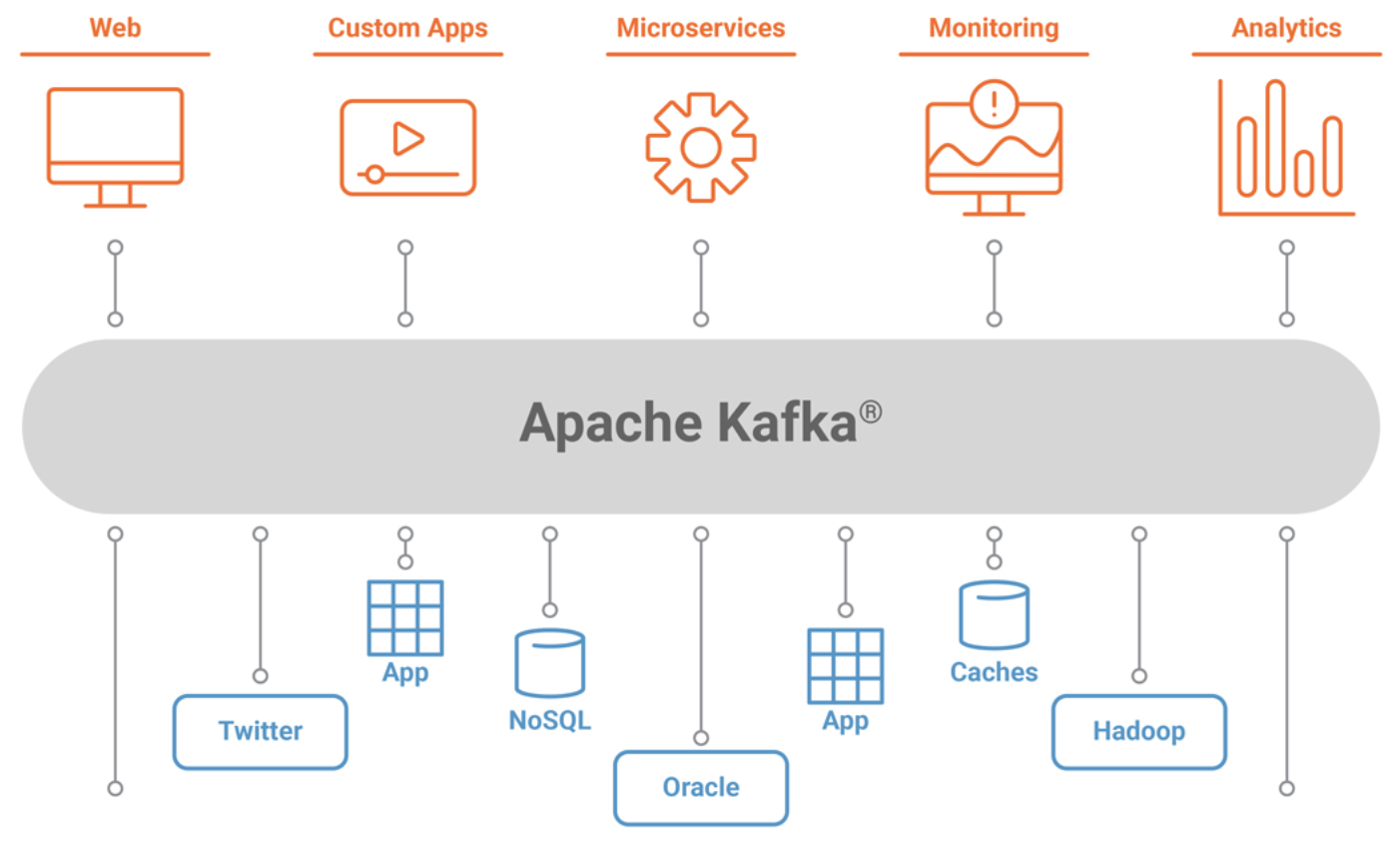
Quelle : davidxiang.com
Die ersten Schritte mit Apache Kafka sind relativ einfach. Der erste Schritt besteht darin, einen Kafka-Cluster einzurichten. Sie können entweder einen Kafka-Cluster auf Ihren eigenen Servern einrichten oder einen verwalteten Kafka-Dienst eines Cloud-Anbieters nutzen. Sobald Sie einen Kafka-Cluster eingerichtet haben, können Sie damit beginnen, Daten mithilfe der Kafka-API oder einer der vielen verfügbaren Client-Bibliotheken zu produzieren und zu konsumieren.
Schlussfolgerung:
Zusammenfassend lässt sich sagen, dass Apache Kafka eine leistungsstarke Plattform für die Echtzeit-Datenverarbeitung ist. Sie ermöglicht das Streamen von Daten in Echtzeit und ist damit ideal für eine Vielzahl von Anwendungsfällen wie Datenpipelines, Echtzeitanalysen und ereignisgesteuerte Architekturen. Kafka ist auf Skalierbarkeit, Fehlertoleranz und niedrige Latenzzeiten ausgelegt, was es zu einer beliebten Wahl für Unternehmen jeder Größe macht. Wenn Sie Ihre Echtzeit-Datenverarbeitung optimieren möchten, ist Apache Kafka definitiv eine Überlegung wert.



